





 Add to Reddit
Add to Reddit

New Cache Structure
L1 Cache
|
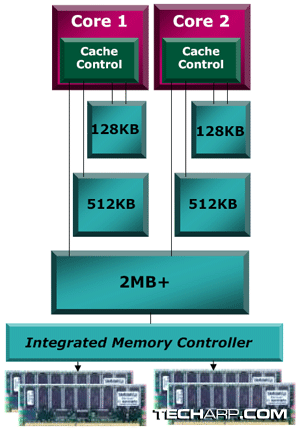
Each core in the Barcelona will have a dedicated 128KB, 2-way set associative L1 cache. This is twice the size of the L1 cache available to each core in the Intel Core 2 processor. The latency for the processor to retrieve data from the L1 cache is 3 clock cycles.
L2 Cache
In the Core 2 design, Intel makes use of a large L2 cache shared between two cores. AMD, however, has chosen to use a smaller, dedicated 512KB L2 cache for each processing core. That means the quad-core Opteron processor will have four separate 512KB L2 caches. These caches are 16-way set associative, and the latency for each core to retrieve data from its L2 cache is 12 clock cycles.
L3 Cache
The Barcelona features a large, shared L3 cache that is at least 2MB in size. This L3 cache will be shared by all cores, whether it's a dual-core or quad-core processor.
This cache is 32-way set associative and is based on a non-inclusive victim cache architecture. The latency for any core to retrieve data from the L3 cache is said to be less than 38 clock cycles. Oddly enough, AMD says the actual latency depends on the clock speed of the south bridge.
Integrated Memory Controller
In the event of a full cache miss (meaning the data requested cannot be found in the L1, L2 and L3 caches), the integrated DDR2 memory controller ensures that the data can be retrieved in less than 60 nanoseconds. All memory ranks will be accessible to the processor cores at the same latency.
Monolithic Design Advantage
The Barcelona's monolithic design allows it to take advantage of its L3 cache which is shared by all four cores. This is quite different from current Intel quad-core processors. However, that's not the whole story. AMD is eager to show that not only does the monolithic design allow much faster sharing of data between all four cores, the integration of the memory controller within the processor allows for much faster data retrieval from system memory.
Let's start with the monolithic design. Take a look at the two processor diagrams below. The monolithic design allows the L3 cache to be shared by all four cores in the Barcelona. In the event that Core 1 needs data stored in Core 3's cache, it can directly probe Core 3's cache and retrieve the data. This allows for high-speed sharing of data between the dedicated caches of all four cores.
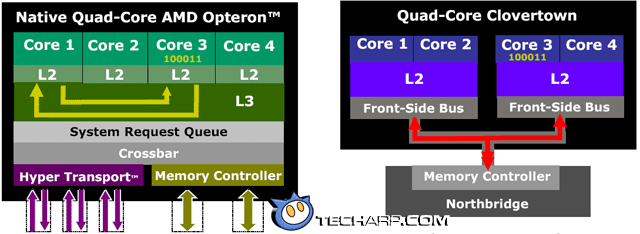
In contrast, the Intel's split-die design and separate memory controller requires a markedly different solution. If the same scenario presents itself, Core 1 will have to send the request to the memory controller (located in the north bridge chip) through the relatively slow front side bus. The memory controller will then probe Core 3's L2 cache, resulting in Core 3 sending the requested data to the memory controller. The data is then forwarded to Core 1. Needless to say, this results in much slower sharing of data.
Of course, AMD deigned to mention that this problem only occurs when data needs to be shared between cores of different processor dies. If data is to be shared between cores of the same processor die, Intel processors will still be faster since the L2 cache is shared by both cores.
Nonetheless, it is obvious to see why a monolithic die design and integrated memory controller is the future. Even if AMD opted for a split-die design, the integration of the memory controller within the processor would have mitigated the loss of performance by avoiding the need to channels data through the slow front side bus.
<<< True Quad-Core, Other Enhancements : Previous Page | Next Page : Improved Power Management, Improved Core Power Management, Advanced Clock Gating >>>